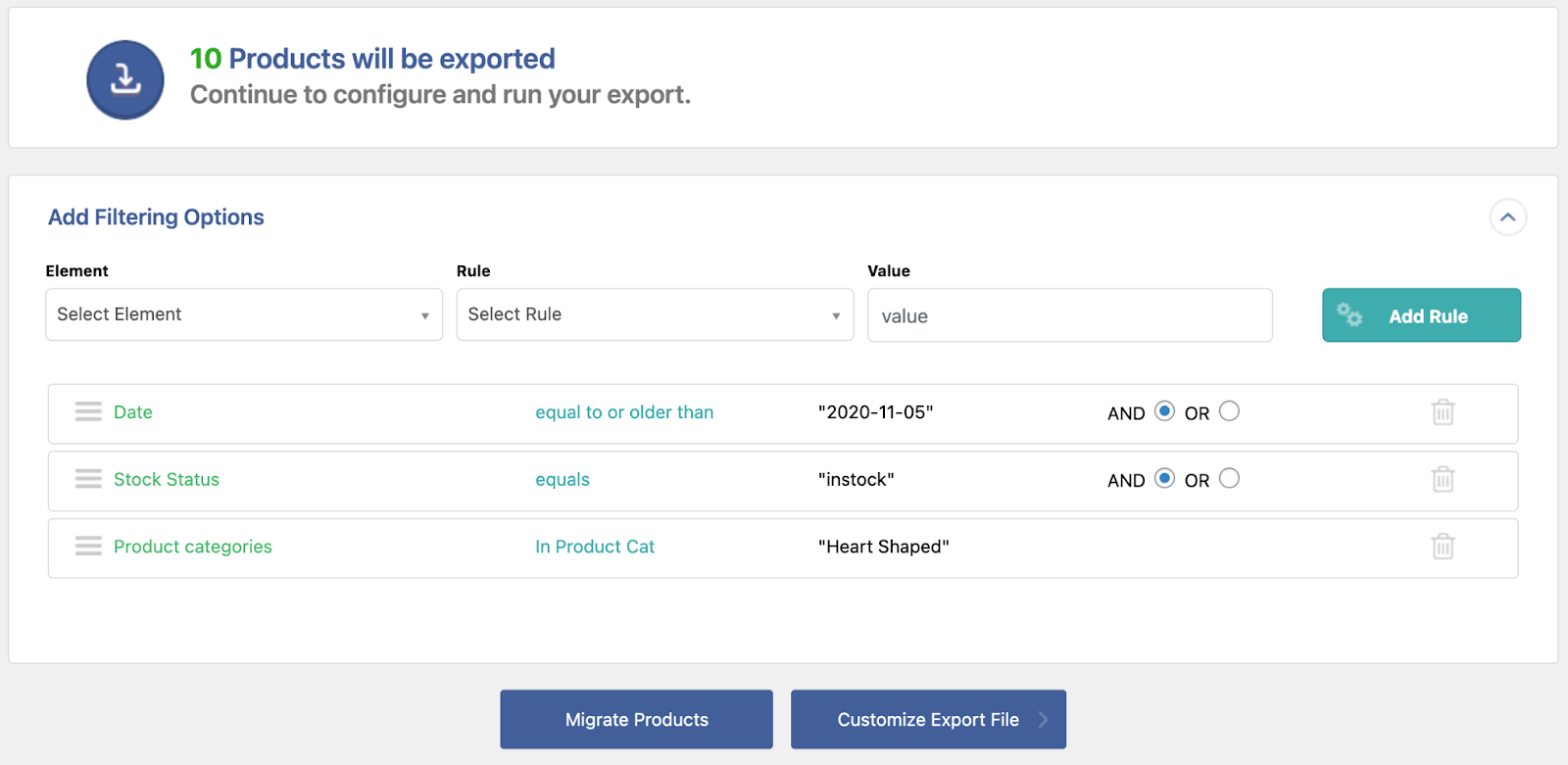
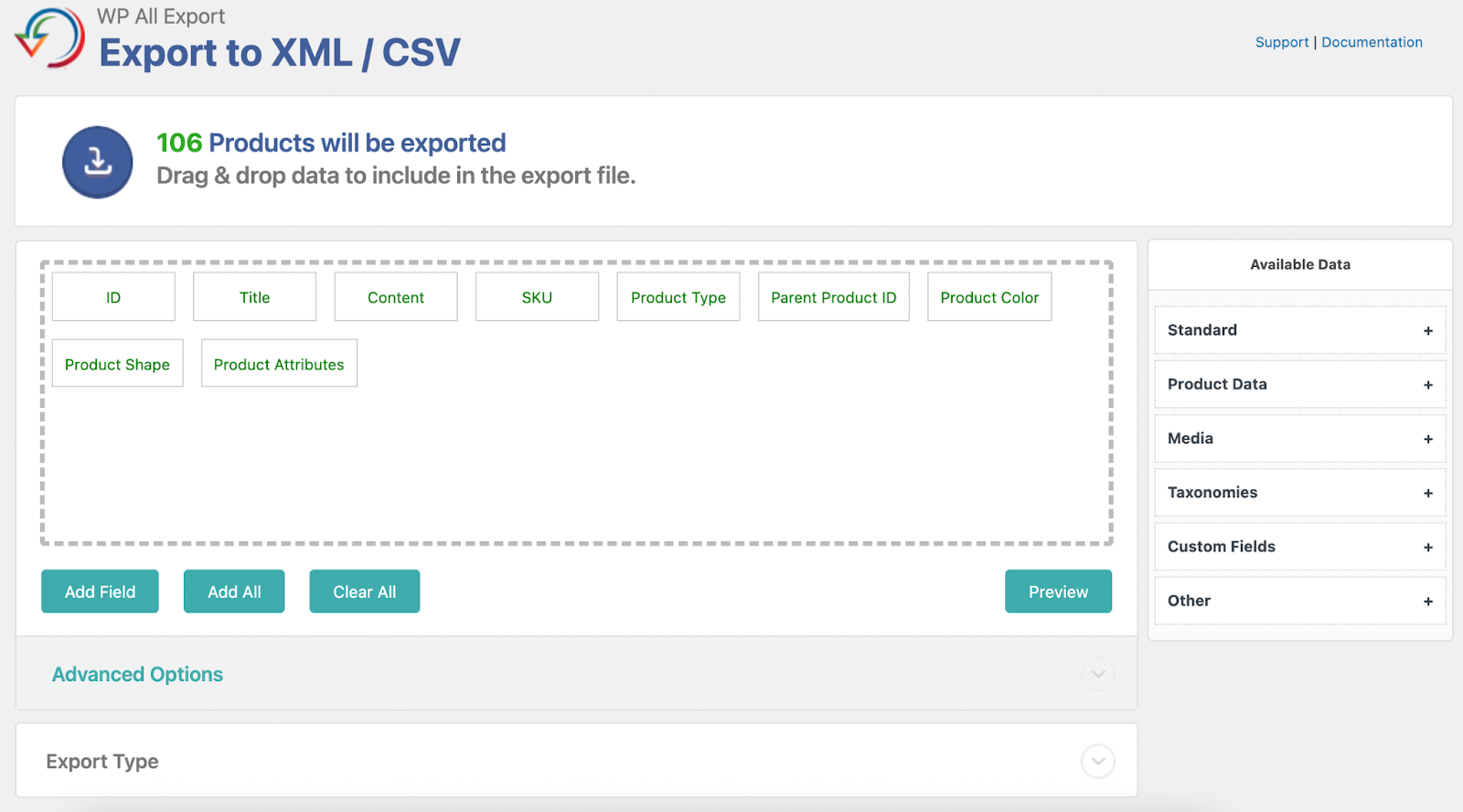
WordPress.com vs WordPress.org: Key Differences
Creating your very own website used to be reserved just for those who were familiar with programming languages like HTML and CSS, but as the world goes forward, the online world evolves too. We have reached the point where anyone can have a fully functional website with just a few clicks.
One of the most famous Content Management Systems (CMS) is WordPress. Why choose WordPress? The main reason is that it’s incredibly simple and easy to use. The simplicity of use helped it rise to the top. With a long and rich WordPress history, it’s become the largest CMS today, running more than a third of all global websites.
You may be wondering, what is WordPress used for? Users can get confused as there exist two instances with the same names, wordpress.com and wordpress.org.
Even though they have the same name, there are many differences between them. Keep reading to understand the differences between wordpress.com and wordpress.org.
WordPress.com
WordPress.com is, in short, a service that will take care of hosting your WordPress website for you. With WordPress.com, a user can create a website, and then relax and focus on other tasks at hand, such as marketing or content creation.
You may be wondering, is WordPress a hosting site? In this case, it is, as it is actually hosting your website.
One of the biggest advantages of WordPress.com is that it is completely free to use. Anyone can sign in and start creating a fully functional website. It will, however, be necessary to upgrade from a free plan to a personal plan if you wish to use a specific domain name and remove the WordPress marketing from your website.
👉 Why Do You Need Hosting for WordPress? >>
If you are, however, in need of a more complex website with more features, you will need to upgrade to a more expensive plan. Some of the features are only available with a more high-priced plan. For example, one of the more handy features that a user can get with WordPress Business plan is to purchase a WordPress theme elsewhere and install it on the website.
Overall, WordPress.com is more suitable for those that are new to the world of websites and hosting, and it is also an appealing option for those users that simply wouldn’t like the responsibility of running their website to fall on their shoulders. It is guaranteed that the site will be up and running at any time.
WordPress.com offers the user a simple way of installing the software and it provides its users additional maintenance of the website.
When you are first accessing WordPress.com interface, you will be greeted and encouraged to create an account.
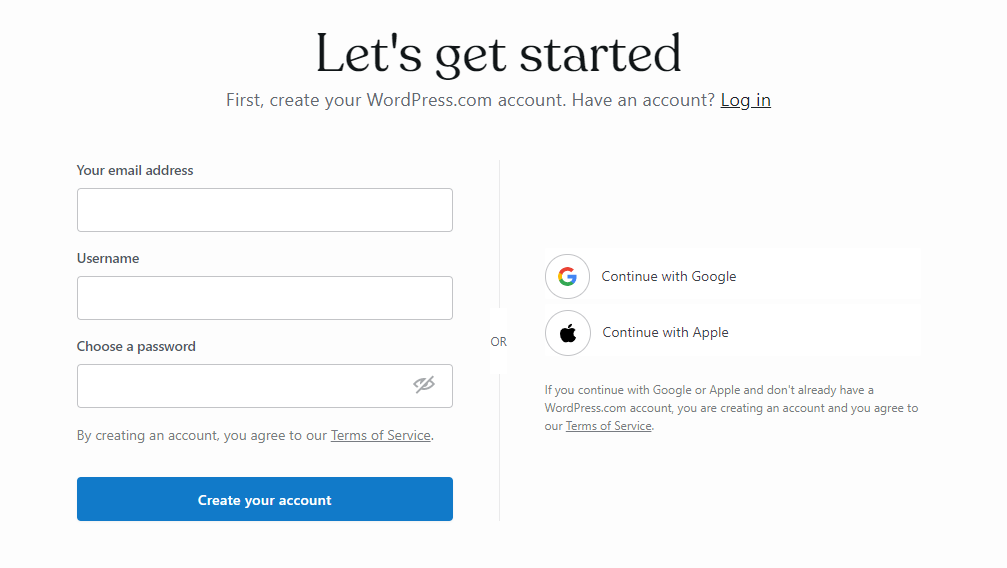
After signing in, you can choose your domain name, and if you plan on registering your domain name elsewhere, you can simply choose the WordPress free option, for-example.wordpress.com. If you already own a domain name, you can connect it to your WordPress.com site through mapping or transfer. That option will be presented to you on the right side of the screen.
Once you are finished with setting up a domain name for your future website, WordPress.com redirects you to choose a payment option. Aside from a free option that you can choose, the cheapest one is a personal plan for $4 per month. With that plan you can get a free domain name for an entire year. Your website will be free of WordPress advertising, and you will get unlimited email support.
Of course, as the price goes higher, the possibilities multiply. With the $45 ecommerce plan, you can have more advanced features such as SEO (search engine optimization) tools and even earn ad revenue from your site.
👉 The Essential Guide to WordPress Plugins >>
And now, the fun can begin. After choosing the payment plan, you will be redirected to an interface where you can create your very own website. You will be given an option to name your website, update your homepage, confirm the email address, and edit the site menu.
From there, you have several convenient options available. For example, you can use the WordPress app for both Android and iOS mobile phones, which enables editing your site on the go. You can also access a large WordPress knowledge base, which can be tremendously helpful. Furthermore, WordPress.com has a large library of copyright-free photos you can use when creating a website.
On the left side of the WP-Admin Dashboard, you can find some account-related functions. If you wish to change your payment plan, you can manage that under the Upgrades section. All the comments users leave on your website can be conveniently found in this section when you click on the Comments link. The appearance of the website, as well as plugins that you have installed or are available to you, can also be accessed from this section.
Everything is simple and ready to be used. For example, if you wish to install a plugin on your website, simply click on the Plugins link. You will be taken to an interface where you can easily install any plugin you want with the click of a button.

It’s really as simple as that — and it’s easy to understand why WordPress.com became so popular in the world of user-friendly web development. But what about WordPress.org?
WordPress.org
WordPress.org is open-source software — its code can be accessed and modified by anyone. WordPress.org is known as self-hosted WordPress. That means that the user has more control over the creation of his or her site.
You can install themes and choose from a variety of plugins to make your site. The user is not limited in any way when choosing from a variety of themes and plugins, which can be significant if you are trying to stand out from the crowd. You will, on the other hand, be responsible for the hosting of your site.
👉 Learn How to Use WordPress With Our Most Helpful WordPress Resources >>
With WordPress.org, you can customize any theme you want, and you can even build your own theme from scratch with the help of CSS and PHP. WordPress.org can make your life easier with features that take care of security, analytics, and more.
If you’re wary of being self-hosted, know that there really isn’t much to be afraid of. There are many WordPress communities and forums dedicated to finding help for any issues that may occur. There are also a number of available resources on WordPress.org as well, both in the form of workshops and articles.

Additionally, hosting companies offer Managed WordPress services that can relieve you of some of those duties.
How to Use WordPress.org to Create a Website
If you choose to create your website with WordPress.org, the first step in the process would be an installation. WordPress is software which you can download from their official WordPress.org website on your device for free. If you already have a cPanel account, you can download and install WordPress in cPanel using Softaculous or Fantastico.
After installing the software, You will be looking at an interface that resembles the one of WordPress.com. On the left, in a darker box, you can access administration functions, such as updates for your WordPress account, plugins, and themes. From there the user can also review all of the comments from his or her WordPress website, which can vastly improve interaction with the visitors of your website.
Installing a plugin or changing its appearance is effortless. In only a few clicks you can completely change the appearance of your website without worrying about losing your content. The possibilities are endless here — creating the content is complicated enough, and with WordPress you can easily decide what looks best for the content of your website simply by trying various themes. It’s as painless as choosing a pair of pants in a dressing room.
You may be wondering, what is the difference between WordPress.com and WordPress.org? And how is all of this significant to me?
There are advantages and disadvantages with both WordPress.com and WordPress.org, and in the end, all that matters is what kind of website you are building and what are you expecting from your CMS.
One of the main polarities in WordPress.org vs. WordPress.com is that with WordPress.org you can host your own website, while if you are using WordPress.com, it will be WordPress.com that is hosting your website. That makes WordPress.com painless if you are just getting started, but it gives you less freedom than its counterpart.
👉 Beginner’s Guide to WordPress Performance Optimization >>
With WordPress.com you can have a simple website in a couple of clicks, but for more complex themes and plugins, the user will have to upgrade his or her payment plan. Besides that, there are not a lot of themes the user can choose from if he or she does not upgrade to a higher payment plan. This can raise some concerns if you are trying to make a distinctive website that will be instantly recognizable.
If you care about the appearance and the variety of plugins, but you would not like to spend a lot of money, then WordPress.org could be a better solution for you. But if you don’t mind that your blog or a website has the same theme as possibly thousands of other websites, and the simplicity of it all is appealing to you, then WordPress.com might be the way to go.
Either way, with either one you get to create a fully functional and great looking website from scratch, without any experience.
However, there is also the option of Managed WordPress. This option lets you have it all — simplicity and a trouble-free experience paired with as much creative freedom as you need.
Consider Managed WordPress Hosting from Hostdedi
Combine the freedom and convenience of WordPress software with a carefree experience of managed website hosting. But what is WordPress hosting? And what is managed WordPress?
Essentially, the term managed hosting describes a service where your hosting provider takes care of the administration and security of your website, as well as keeping it up and running steadily. As we already know, WordPress websites make up more than a third of all websites on the internet, and a convenient option for WordPress users is to have managed WordPress hosting.
Some features that make Hostdedi fully managed WordPress so convenient include:
- Security monitoring that is always on.
- Support from WordPress experts 24/7 every day of the year.
- A built-in Content Delivery Network (CDN) with 22 locations.
- And advanced caching for ultrafast loading of the website.
Hostdedi also offers image compression which can significantly improve the browser loading time. Premium tools with Hostdedi managed WordPress plans include Visual Compare, WP Merge, iThemes Security Pro, iThemes Sync, TinyPNG, and Qubely Pro.
What Hostdedi doesn’t have are overage fees, traffic limits, and metered pageviews.
Hostdedi offers a variety of fully managed WordPress hosting plans, and with every plan you choose, you have a staging environment, 30-day backups, and unlimited email accounts. You also have an option of a 30-day money back guarantee, so you can be confident when choosing your plan.
Give it a try. Start your free two-week trial of managed WordPress today.

Power up your sites and stores with custom-built technology designed to make every aspect of the digital commerce experience better. Make your digital commerce experience better with Hostdedi. Visit Hostdedi.net today and see how we can help.